To inaugurate this blog, I will present a new W3C recommendation that I found very interesting: JSON for Linking Data ( JSON-LD)1. This presentation will also serve as an introduction to Linked Data (also known as the Web of Data) that will be, for sure, a recurrent subject of this blog.
Problem
How data from different sources can easily be exploited? For 25 years now, the Web allows human readers, through links, to navigate from site to site and to visualize multiple documents (e.g. images) within the same HTML page. Information extraction from plain HTML pages is usually not a difficult task for us humans; however, for computers, it is.
Information extraction from text can be done using Natural Language Processing techniques which are quite complex, not always precise but nevertheless very useful when there is no alternative. A better solution, when the publisher agrees, is either to provide additional representations (JSON, Turtle RDF, etc.) or to annotate the HTML page (using for instance RDFa). This approach is appealing because HTML pages are often generated from structured data. As Tim Berners Lee says, what we want is access to this “raw” data. In this article, we focus on this approach and present how data from multiple sources can be merged.
JSON
JSON is, as of today, the most popular format among Web developers. It is concise and simple. Here are three JSON files taken from three different sites:
#project_v1
{"title": "Super project",
"home": "http://super-project.example.com/",
"developers": [
{"name": "John Doe"},
{"name": "Roger Smith"}
]
}
#comment_v1
{"id": "http://blog.example.net/dupont/comment/5",
"author": {"fullname": "Francis Dupont"},
"about": {
"type": "Project",
"homepage": "http://super-project.example.com/"
},
"comment_en": "Super-project is a masterpiece.",
"comment_fr": "Super-project est un chef-d'œuvre.",
"type": "Comment"
}
#person_v1
{"full_name": "John Doe",
"photo": "http://doe.example.org/john.jpg",
"blog": "http://blog.example.org/",
"projects": [
{"homepage": "http://super-project.example.com/"},
{"homepage": "http://example.org/doe/otherproject"}
]
}
Because JSON is easy to read, you may have already understood that these files describe a project, a comment about it and one of its developers.
Our objective is to automatically merge their data before making the following query: “What are the blogs of the developers of the project this comment is talking about?”. Ok, you can certainly already answer this query with good confidence. But our point here is to delegate this task to a generic program, so some precisions are needed.
Identifiers
These data come from different sites, so we cannot be certain that two identical names refer to the same person. It is a well-understood problem that administrations and large websites with millions of user accounts are familiar with. It can be solved by giving global identifiers to these persons. We will use global identification solution offered by the Web: the Universal Resource Identifier (URI).
Here is a new version of the JSON files that gives URIs to these persons:
#project_v2
{"title": "Super project",
"home": "http://super-project.example.com/",
"developers": [
{"name": "John Doe",
"href": "http://doe.example.org/john/profile#me"
},
{"name": "Roger Smith",
"href": "http://smith.example.org/roger/profile#me"
}
]
}
#comment_v2
{"id": "http://blog.example.net/dupont/comment/5",
"author": {
"fullname": "Francis Dupont",
"id": "http://dupont.example.net/#francis"
},
"about": {
"type": "Project",
"homepage": "http://super-project.example.com/"
},
"comment_en": "Super-project is a masterpiece.",
"comment_fr": "Super-project est un chef-d'œuvre.",
"type": "Comment"
}
#person_v2
{"full_name": "John Doe",
"href": "http://doe.example.org/john/profile#me",
"photo": "http://doe.example.org/john.jpg",
"blog": "http://blog.example.org/",
"projects": [
{"homepage": "http://super-project.example.com/"},
{"homepage": "http://example.org/doe/otherproject"}
]
}
Vocabulary
Some precisions are still needed: what do we mean by “href”, “id”, “name”, “fullname”, “full_name”, etc.? Are these strings something referring to the same things? How can a program know that they are equivalent?
Again, the idea is to identify globally these properties. If two properties map to the same URI, they are equivalent2. By mapping, for instance, the properties “name”, “fullname” and “full_name” to the URI http://xmlns.com/foaf/0.1/name, we known that these terms are equivalent. In addition, because this URI is an URL, it locates their definition.
How are these terms mapped to URIs in practice? It is where JSON-LD enters. JSON-LD introduces the notion of context 3: we just need to provide a link to the context file, either inside the JSON file, or in HTTP header or by a tiers method4.
For instance, the project description file is modified as follows:
#project_v2.5
{"@context": "http://example.com/project.jsonld",
"title": "Super project",
"home": "http://super-project.example.com/",
"developers": [
{"name": "John Doe",
"href": "http://doe.example.org/john/profile#me"
},
{"name": "Roger Smith",
"href": "http://smith.example.org/roger/profile#me"
}
]
}
Here are the three context files (I do not go here into details but I encourage you to look at the specification that is notable for its accessibility):
#project_ctx
{"@context": {
"foaf": "http://xmlns.com/foaf/0.1/",
"doap": "http://usefulinc.com/ns/doap#",
"href": "@id",
"type": "@type",
"developers": "doap:developer",
"name": "foaf:name",
"home": {
"@id": "foaf:homepage",
"@type": "@id"
},
"title": "doap:name",
"Project": "doap:Project"
}
}
#comment_ctx
{"@context": {
"foaf": "http://xmlns.com/foaf/0.1/",
"sioc": "http://rdfs.org/sioc/ns#",
"sioct": "http://rdfs.org/sioc/types#",
"dcterms": "http://purl.org/dc/terms/",
"doap": "http://usefulinc.com/ns/doap#",
"id": "@id",
"type": "@type",
"fullname": "foaf:name",
"author": "dcterms:author",
"Comment": "sioct:Comment",
"comment_en": {
"@id": "sioc:content",
"@language": "en"
},
"comment_fr": {
"@id": "sioc:content",
"@language": "fr"
},
"about": "sioc:about",
"Project": "doap:Project",
"homepage": {
"@id": "foaf:homepage",
"@type": "@id"
}
}
}
#person_ctx
{"@context": {
"foaf": "http://xmlns.com/foaf/0.1/",
"doap": "http://usefulinc.com/ns/doap#",
"href": "@id",
"type": "@type",
"full_name": "foaf:name",
"photo": {
"@id": "foaf:img",
"@type": "@id"
},
"blog": {
"@id": "foaf:weblog",
"@type": "@id"
},
"projects": {
"@reverse": "doap:developer",
"@type": "doap:Project"
},
"homepage": {
"@id": "foaf:homepage",
"@type": "@id"
}
}
}
Graph
In the two previous sections, we emphasized the use of URIs to identify entities (resources) and properties. By doing it, we set up unidirectional typed links between these resources. Indeed, in these descriptions, (source) resources are linked to other (target) resources by properties (types). Recall that multiple links constitutes a web so this practice leads naturally to what we called the Web of Data, which is composed of Linked Data. This can be seen as an extension of the Web of documents where we can talk about everything, not just documents, and where we give unambiguous types to links.
The JSON-LD data model, closely related to the Resource Description Framework (RDF) 5, relies on these unidirectional typed links and forms consequently a labeled directed graph. A graph is a flexible mathematical structure that easily merges with other graphs. Thus graphs offer a good solution for merging multiple data sources.
Let us go back to practice. Now that data are enough precise, we load them into a RDF graph with the RDFlib Python library:
# JSON files loaded above...
# Context files are URIs
from rdflib import Graph
graph = Graph()
graph.parse(data=project_v2, context=project_ctx, format="json-ld")
graph.parse(data=person_v2, context=person_ctx, format="json-ld")
graph.parse(data=comment_v2, context=comment_ctx, format="json-ld")
This graph can be represented as follows (click on the picture to zoom
in):
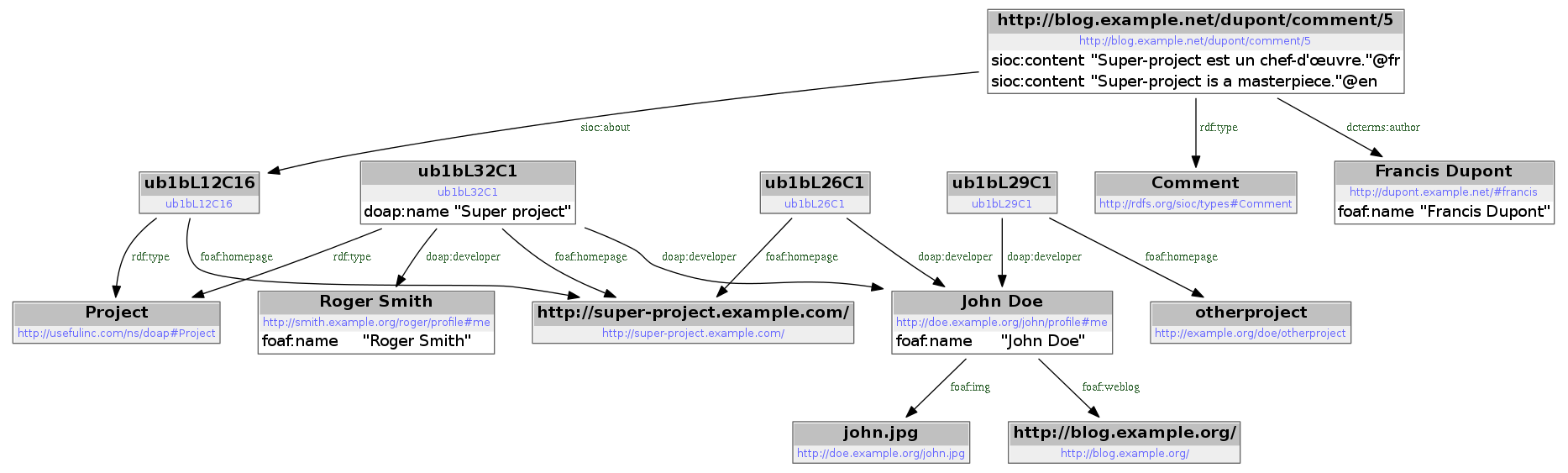
You may have noticed that four nodes have strange names starting with “ub1bL”: they do not have URIs, they are blank nodes. Furthermore, they all have a property “foaf:homepage” that targets the homepage of “Super Project”. These nodes all refer to the project “Super Projet” but, because they do not have a common URI, the RDF library cannot deduce this fact. This will make our query a little bit more complex: we will use two variables («p1» and «p2») to represent the project instead of one.
RDF graphs have their own query language: SPARQL. Here is our query and its results:
>>> blog_request = """
... SELECT DISTINCT ?developer ?blog
... WHERE {
... <http://blog.example.net/dupont/comment/5> sioc:about ?p1 .
... ?p1 foaf:homepage ?homepage .
... ?p2 foaf:homepage ?homepage .
... ?p2 doap:developer ?developer .
... OPTIONAL { ?developer foaf:weblog ?blog }
... }"""
>>> results = graph.query(blog_request)
>>> for dev, blog in results:
... if blog is not None:
... print "%s's blog: %s" % (str(dev), str(blog))
... else:
... print "%s's blog is unknown" % str(dev)
http://smith.example.org/roger/profile#me's blog is unknown
http://doe.example.org/john/profile#me's blog: http://blog.example.org/
Conclusion
The main objective of the Web of Data is to interconnect structured data across web sites so as to go beyond the silo effect caused by many Web 2.0 sites.
Many introductions to Linked Data starts from RDF. By starting from JSON, I hope that some Web developers will find it more concrete.
Finally, experienced users may have noticed that I quickly switch from JSON-LD to RDF. This is because I am personally more focused on RDF than JSON-LD in my current projects in this domain. However, it is perfectly possible to adopt a more JSON-LD-centric point of view and to make some transformations at this level without using SPARQL and other RDF formats.
Links
- The next Web, Tim Berners at TED.
- Introduction to JSON-LD by one of its authors.
- My Object Linked Data Mapper project based on JSON-LD : https://github.com/oldm/OldMan/.
- Linked data patterns.
- Online courses: Euclid project.
- Google I/O 2013 - From Structured Data to the Knowledge Graph
-
JSON stands for JavaScript Object Notation. ↩
-
If they do not have the same identifiers, reasoning is needed to infer if they are equivalent or not. This is an advanced topic. ↩
-
The JSON-LD context is a profile (RFC 6906) in the terms of the IETF. ↩
-
If, for instance, you have written your own context file. ↩
-
JSON-LD fully supports RDF and extends it a little bit. Conversion from RDF to JSON-LD is lossless. In the other direction, there is one thing to know: JSON-LD accepts non-URI (blank nodes) properties while RDF forbids them. In practice, if a property has disappeared after the conversion from JSON-LD to RDF, it indicates that the mapping between the property key and an URI is missing in the JSON-LD context file. For further details, see the section 9 of the spec.. ↩