Pour inaugurer ce blog, je vais vous parler d’une nouvelle recommandation du W3C que je trouve très intéressante : il s’agit de JSON for Linking Data ( JSON-LD)1. Cela me donne également l’occasion d’introduire la thématique du Web des données (Linked Data) qui sera, à coup sûr, un thème récurrent de ce blog.
Problème
Commençons par la question suivante : comment peut-on faciliter l’exploitation de données provenant de sources différentes? Depuis déjà 25 ans, le Web apporte une solution élégante aux lecteurs humains, en leur permettant, par l’intermédiaire de liens, de naviguer aisément de site en site ou de visualiser plusieurs documents (comme des images) dans la même page HTML. L’extraction d’information à partir de ces pages HTML est, pour nous autres humains, une tâche assez facile; toutefois, il n’en va pas de même pour les machines. Pour que ces dernières puissent exploiter ces données, il existe deux grandes approches :
- Un site Web peut proposer une autre représentation (JSON, Turtle RDF, etc.) ou enrichir la page HTML (avec, par exemple, des annotations RDF) afin qu’un programme client puisse en extraire plus facilement les données. Cette approche est d’autant plus souhaitable que les pages HTML sont souvent générées à partir de données bien structurées, généralement stockées en base de données. Ce sont avant tout ces données riches qui nous intéressent. Nous allons nous concentrer aujourd’hui sur cette approche et voir comment les données issues de plusieurs sites peuvent être fusionnées.
- Le programme client peut avoir recours à des techniques de traitement automatique du langage naturel. Ces techniques sont plus complexes, moins précises mais néanmoins très utiles car elles ne nécessitent aucun changement de la part du site Web. Les moteurs de recherche ont bien entendu massivement recours à ces techniques car une large part des données publiées sur le Web n’est disponible que sous une forme peu structurée; néanmoins ils n’en sont pas moins friands de données structurées.
JSON
Ces dernières années, JSON est le format en vogue auprès des développeurs Web. Il est tout simplement concis et très simple. Sans plus attendre, voici les trois fichiers JSON issus de sites différents dont nous allons extraire les informations :
#project_v1
{"title": "Super project",
"home": "http://super-project.example.com/",
"developers": [
{"name": "John Doe"},
{"name": "Roger Smith"}
]
}
#comment_v1
{"id": "http://blog.example.net/dupont/comment/5",
"author": {"fullname": "Francis Dupont"},
"about": {
"type": "Project",
"homepage": "http://super-project.example.com/"
},
"comment_en": "Super-project is a masterpiece.",
"comment_fr": "Super-project est un chef-d'œuvre.",
"type": "Comment"
}
#person_v1
{"full_name": "John Doe",
"photo": "http://doe.example.org/john.jpg",
"blog": "http://blog.example.org/",
"projects": [
{"homepage": "http://super-project.example.com/"},
{"homepage": "http://example.org/doe/otherproject"}
]
}
Le JSON étant assez facile à lire, vous avez peut-être déjà compris qu’il s’agissait de la description d’un projet, d’un commentaire à son sujet et d’informations concernant un de ses développeurs.
Notre objectif est de fusionner automatiquement ces données pour pouvoir ensuite faire une requête du type : «Quels sont les blogs des développeurs du projet dont parle ce commentaire?». Je suppose que vous êtes déjà capable de répondre à cette question de façon quasi-certaine. Par contre, pour déléguer cette tâche à un programme générique, il va nous falloir apporter quelques précisions.
Identifiants
Comme ces informations viennent de trois sites différents, nous ne pouvons pas être certains que deux noms de personnes désignent la même personne dès que l’on sort d’un cadre local sans prendre en compte d’autres informations2. C’est un problème bien connu des administrations et des sites ayant des millions de comptes utilisateurs. Nous avons besoin d’identifiants globaux pour désigner ces personnes. Pour résoudre ce problème, nous allons utiliser le mécanisme d’identification globale offert par le Web : l’Universal Resource Identifier (URI).
Voici les nouvelles versions modifiées des fichiers JSON donnant une URI à chacune des personnes :
#project_v2
{"title": "Super project",
"home": "http://super-project.example.com/",
"developers": [
{"name": "John Doe",
"href": "http://doe.example.org/john/profile#me"
},
{"name": "Roger Smith",
"href": "http://smith.example.org/roger/profile#me"
}
]
}
#comment_v2
{"id": "http://blog.example.net/dupont/comment/5",
"author": {
"fullname": "Francis Dupont",
"id": "http://dupont.example.net/#francis"
},
"about": {
"type": "Project",
"homepage": "http://super-project.example.com/"
},
"comment_en": "Super-project is a masterpiece.",
"comment_fr": "Super-project est un chef-d'œuvre.",
"type": "Comment"
}
#person_v2
{"full_name": "John Doe",
"href": "http://doe.example.org/john/profile#me",
"photo": "http://doe.example.org/john.jpg",
"blog": "http://blog.example.org/",
"projects": [
{"homepage": "http://super-project.example.com/"},
{"homepage": "http://example.org/doe/otherproject"}
]
}
Vocabulaire
Avant de pouvoir requêter ces données, il est nécessaire d’apporter une dernière précision: qu’entendons par «href», «id», «name», «fullname», «full_name», etc.? S’agit-il parfois de la même chose? Comment un programme peut-il le savoir?
Comme pour les noms de personnes, l’idée est d’associer des identifiants globaux à ces propriétés. Ainsi lorsque deux propriétés ont le même identifiant alors elles parlent de la même chose3. En associant par exemple les propriétés «name», «fullname» et «full_name» à l’URI http://xmlns.com/foaf/0.1/name, on sait désormais que ces termes sont équivalents et, en bonus comme c’est une URL, on a accès à leur définition.
Comment fait-on en pratique pour associer des termes à des URI? C’est là que JSON-LD entre en jeu. JSON-LD introduit la notion de contexte4 : il suffit d’ajouter un lien vers un fichier de contexte, soit à l’intérieur du fichier JSON,soit dans une entête HTTP ou soit par une méthode tierce5.
Par exemple, la description du projet devient la suivante :
#project_v2.5
{"@context": "http://example.com/project.jsonld",
"title": "Super project",
"home": "http://super-project.example.com/",
"developers": [
{"name": "John Doe",
"href": "http://doe.example.org/john/profile#me"
},
{"name": "Roger Smith",
"href": "http://smith.example.org/roger/profile#me"
}
]
}
Voici les trois fichiers de contexte (je n’entre pas ici dans les détails mais vous pouvez consulter la spécification qui, je tiens à le souligner, est remarquable par son accessibilité):
#project_ctx
{"@context": {
"foaf": "http://xmlns.com/foaf/0.1/",
"doap": "http://usefulinc.com/ns/doap#",
"href": "@id",
"type": "@type",
"developers": "doap:developer",
"name": "foaf:name",
"home": {
"@id": "foaf:homepage",
"@type": "@id"
},
"title": "doap:name",
"Project": "doap:Project"
}
}
#comment_ctx
{"@context": {
"foaf": "http://xmlns.com/foaf/0.1/",
"sioc": "http://rdfs.org/sioc/ns#",
"sioct": "http://rdfs.org/sioc/types#",
"dcterms": "http://purl.org/dc/terms/",
"doap": "http://usefulinc.com/ns/doap#",
"id": "@id",
"type": "@type",
"fullname": "foaf:name",
"author": "dcterms:author",
"Comment": "sioct:Comment",
"comment_en": {
"@id": "sioc:content",
"@language": "en"
},
"comment_fr": {
"@id": "sioc:content",
"@language": "fr"
},
"about": "sioc:about",
"Project": "doap:Project",
"homepage": {
"@id": "foaf:homepage",
"@type": "@id"
}
}
}
#person_ctx
{"@context": {
"foaf": "http://xmlns.com/foaf/0.1/",
"doap": "http://usefulinc.com/ns/doap#",
"href": "@id",
"type": "@type",
"full_name": "foaf:name",
"photo": {
"@id": "foaf:img",
"@type": "@id"
},
"blog": {
"@id": "foaf:weblog",
"@type": "@id"
},
"projects": {
"@reverse": "doap:developer",
"@type": "doap:Project"
},
"homepage": {
"@id": "foaf:homepage",
"@type": "@id"
}
}
}
Graphe
Dans les deux sections précédentes, nous avons motivé l’utilisation d’URIs pour identifier les entités (ressources) dont on parle ainsi que leurs propriétés. En procédant de la sorte, nous venons d’établir des liens unidirectionnels typés entre ces ressources. En effet, pour être décrite, une ressource source est liée à une ressource cible par l’intermédiaire d’une propriété, formant ainsi un lien. Et qui dit liens, dit toile, dit web. C’est pour cela que l’on parle d’unWeb de données ou de données liées. Celui-ci peut être vu comme une extension du Web des documents où l’on parle de tout et non simplement de documents (passage de l’URL à la notion plus générale d’URI) et où l’on explicite le type des liens.
Le modèle de données de JSON-LD, étroitement lié à celui du Resource Description Framework (RDF) 6, repose donc sur des liens unidirectionnels typés et forme en conséquence un graphe dirigé étiqueté. Un graphe est une structure mathématique flexible qui fusionne très facilement avec d’autres graphes. Elle se prête donc bien à l’agrégation de différentes sources de données.
Revenons à la pratique. Maintenant que toutes les informations nécessaires sont disponibles, les données peuvent être chargées dans un graphe RDF à l’aide de la bibliothèque RDFlib (Python) :
# JSON files loaded above...
# Context files are URIs
from rdflib import Graph
graph = Graph()
graph.parse(data=project_v2, context=project_ctx, format="json-ld")
graph.parse(data=person_v2, context=person_ctx, format="json-ld")
graph.parse(data=comment_v2, context=comment_ctx, format="json-ld")
En voici une représentation graphique (cliquer sur l’image pour zoomer):
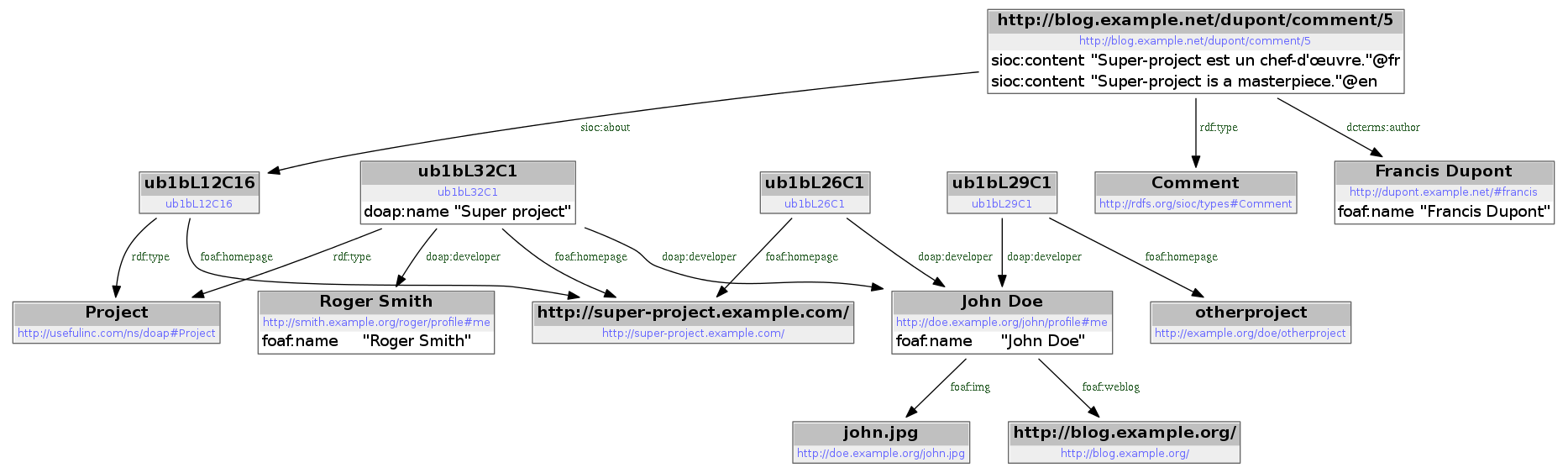 On y remarque 4 nœuds avec des noms étranges commençant par «ub1bL» : il
s’agit de nœuds anonymes (blank nodes) qui, de plus, ont tous une
propriété «foaf:homepage» pointant vers la page d’accueil du projet
«Super Project». Vous l’aurez compris, ces quatre nœuds représentent
tous le projet «Super Projet», mais faute d’avoir une URI commune, la
bibliothèque RDF est incapable de le déduire. Cela va compliquer un peu
notre requête : on aura deux variables («p1» et «p2») au lieu d’une.
On y remarque 4 nœuds avec des noms étranges commençant par «ub1bL» : il
s’agit de nœuds anonymes (blank nodes) qui, de plus, ont tous une
propriété «foaf:homepage» pointant vers la page d’accueil du projet
«Super Project». Vous l’aurez compris, ces quatre nœuds représentent
tous le projet «Super Projet», mais faute d’avoir une URI commune, la
bibliothèque RDF est incapable de le déduire. Cela va compliquer un peu
notre requête : on aura deux variables («p1» et «p2») au lieu d’une.
Les graphes RDF ont leur propre langage de requête standard :SPARQL. Voici notre requête et ses résultats :
>>> blog_request = """
... SELECT DISTINCT ?developer ?blog
... WHERE {
... <http://blog.example.net/dupont/comment/5> sioc:about ?p1 .
... ?p1 foaf:homepage ?homepage .
... ?p2 foaf:homepage ?homepage .
... ?p2 doap:developer ?developer .
... OPTIONAL { ?developer foaf:weblog ?blog }
... }"""
>>> results = graph.query(blog_request)
>>> for dev, blog in results:
... if blog is not None:
... print "%s's blog: %s" % (str(dev), str(blog))
... else:
... print "%s's blog is unknown" % str(dev)
http://smith.example.org/roger/profile#me's blog is unknown
http://doe.example.org/john/profile#me's blog: http://blog.example.org/
Conclusion
L’objectif du Web des données est d’interconnecter les données structurées entre les sites Web et donc de dépasser le phénomène des silos si présent dans le Web 2.0.
La plupart des introductions au Web des données débutent avec RDF. En partant de JSON, j’espère que des développeurs Web trouveront cette introduction plus concrète.
Pour finir, je tiens à préciser que mes projets actuels dans ce domaine sont centrés davantage sur RDF que sur JSON-LD et c’est pour cette raison que je suis rapidement passé de l’un à l’autre. Néanmoins, il est tout à fait possible d’avoir un point de vue plus centré sur JSON-LD et d’effectuer un certain nombre de transformations à ce niveau sans avoir recours à SPARQL ni à d’autre format RDF.
Pour en savoir plus
- The next Web, Tim Berners at TED.
- Présentation de JSON-LD en dessins par l’un de ses auteurs.
- Mon projet d’Object Linked Data Mapper s’appuyant sur JSON-LD : https://github.com/oldm/OldMan/
- Introduction au Web des données (vidéo, diapos) et présentation de l’ensemble des briques technologiques du Web sémantiquepar Fabien Gandon.
- Linked data patterns.
- Cours en ligne : Projet Euclid.
- Google I/O 2013 - From Structured Data to the Knowledge Graph.
-
JSON est l’abréviation deJavaScript Object Notation. ↩
-
En observant que la description de John Doe mentionne le projet, la probabilité qu’il s’agisse de bien de la même personne augmente de manière significative. ↩
-
Si, dans le cas contraire, elles ont deux identifiants différents, il faudra raisonner pour savoir si elles parlent de la même chose ou non. C’est évidemment plus compliqué et cela sort du cadre de cet article. ↩
-
Le contexte JSON-LD est un profile (RFC 6906) au sens de l’IETF. ↩
-
Si par exemple vous avez écrit votre propre fichier de contexte. ↩
-
JSON-LD supporte tout RDF, et l’étend un peu afin de bien s’intégrer dans l’écosystème JSON. Le passage de RDF vers JSON-LD se fait sans perte. Dans l’autre sens, il y a un point à connaître : JSON-LD tolère que certaines clés (propriétés) ne soient pas liées à des URI, ce qui est interdit en RDF où les propriétés ne peuvent pas être des nœuds anonymes (blank nodes). En conséquence, si l’on souhaite vraiment que ces clés soient conservées lors d’une sérialisation dans un format RDF, il est indispensable de les convertir en URI, d’une manière ou d’une autre. La disparition d’une propriété suite la conversion d’un document JSON-LD vers RDF indique donc qu’il manque une règle de correspondance clé-URI dans le contexte JSON-LD. Pour plus d’explications, consultez la section 9 de la spécification. ↩